public The search appliance general and default settings
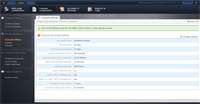
Using the General settings screen, you can manage the key settings of the search appliance. If you don’t provide any values, the default ones will be applied by the system. Please note that some of the settings could be overridden by the crawler or index settings To review the general setting, you need to follow the steps below:
- Log in to the WordFrame Integra Core Administration
- Click on the "Builder" tab in the upper left corner
- Click on the "Content components" menu in the main navigation bar
- Click on the “General settings” link in “Search appliance” section on the left of the screen
The grid presents the following information:
user-agent name Description: This value defines how the search appliance crawler should present itself, when requesting web pages.. recrawl period Description: The default start period for recrawling a single webpage. minimum recrwal period Description: The minimal period for revisiting and recrawling one unique URL. crawler connection timeout Description: When this period exceeds, the crawoler will terminate the HTTP request, of it is still not processed. maximum size of the crawled file Description: Limits the crawler to request and index only files up to this size. default wait between requests Description: Depends on the web server load that you want o inflict during the crawling and indexing processes. indexing batch size Description: Number of items indexed at a single pass. apply robots.txt rules Description: Robots.txt is a file that should be in the main folder of the domain. It can be reviewed by typing in your browser http://domain.com/robots.txt. This file purpose is to set rules for the search crawlers/bots, how to crawl the pages and documents under the corresponding domain. apply robots metatags rules Description: Robots behavior can be managed on page basis with a html metatag included in the page’s HEAD. apply “no-index” html comments rule Description: If it is checked, the page content between <!—BEGIN NO INDEX --> and <! – END NO INDEX --> html comment lines will not be indexede. ”recrawl on error” period Description: The period (in hours) to recrawl a URL if encountered an error. document index parse timeout Description: The period to wait for an indexing iFilter to extract plain text from a document.
Last edited by Boz Zashev on 26 Oct 2010 | Rev. 4 |
This page is
public |
Views: 1
Comments:
0 |
Filed under:
Content components |
Tags: